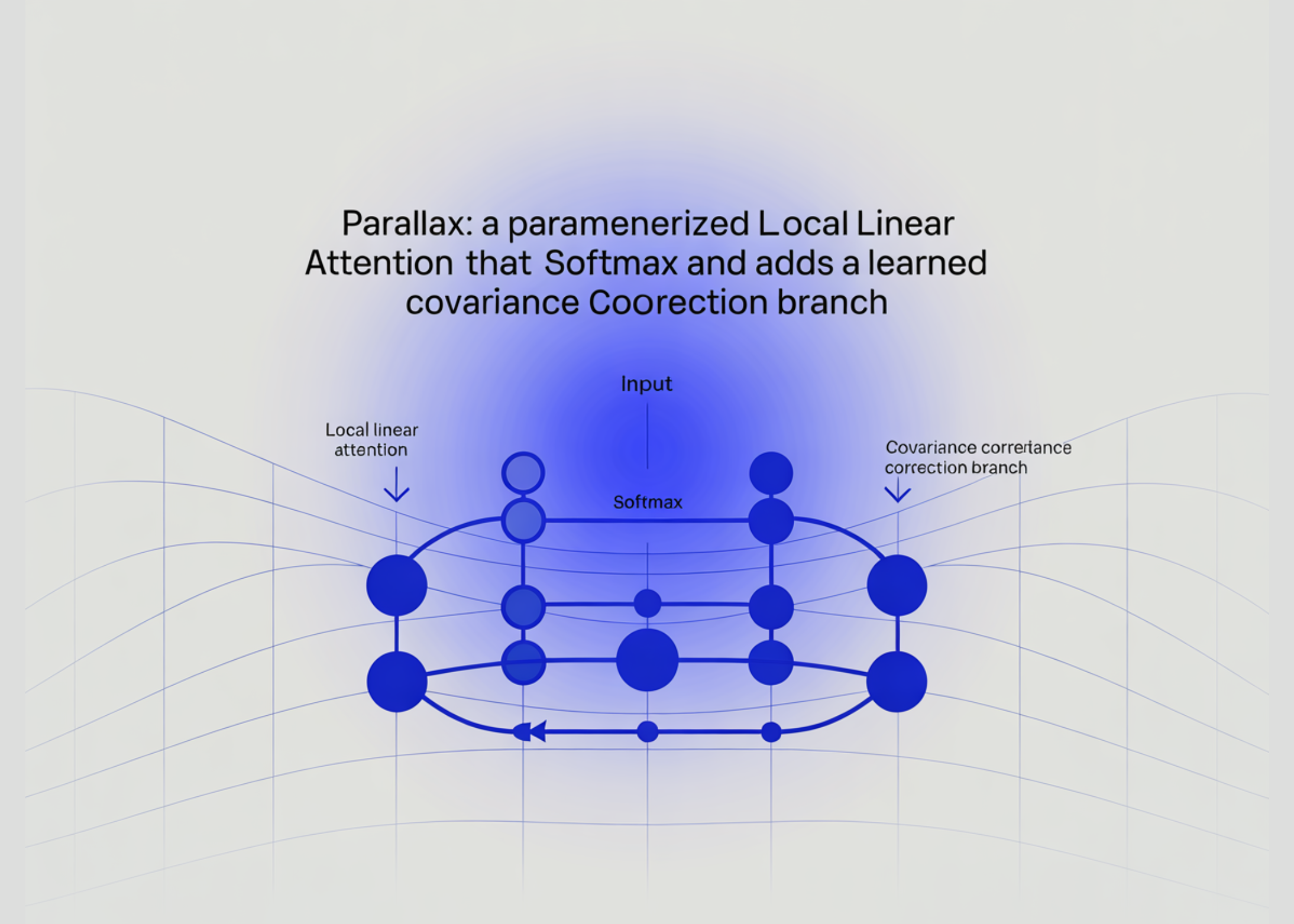
Segun MarkTechPost (AI/ML News), un equipo compuesto por investigadores de la Universidad de Northwestern, Tilde Research y la Universidad de Washington ha presentado una nueva arquitectura de atención llamada Parallax. Esta propuesta busca mejorar la eficiencia de los modelos de lenguaje mediante una adaptación inteligente del mecanismo de atención clásico del Transformer, sin eliminarlo. Desde 2017, el núcleo de atención del Transformer ha permanecido prácticamente inmutable, y la mayoría de los avances han buscado sustituir directamente el softmax. Parallax, en cambio, mantiene el softmax y añade una rama correctora aprendida, permitiendo un equilibrio entre precisión y rendimiento.
La base de Parallax se encuentra en el enfoque de regresión en tiempo de prueba, donde la atención se interpreta como un solver que ajusta valores de salida basados en pares clave-valor. En este contexto, los claves representan datos de entrenamiento, los valores son etiquetas y la consulta corresponde a un punto de evaluación. El softmax, tradicionalmente, se ve como un estimador no paramétrico conocido como Nadaraya-Watson, que asigna una función constante local a cada consulta. Parallax mejora este modelo al sustituir la estimación constante por una función lineal local, lo cual se ha demostrado que reduce el error cuadrático integral de manera estricta. Este cambio ofrece una mejor distribución entre sesgo y varianza, optimizando así el almacenamiento y recuperación de información en memorias asociativas.
Aunque esta mejora teórica es sólida, el enfoque original de LLA (Local Linear Attention) presenta limitaciones al escalar. Para cada consulta, se debe resolver un sistema lineal, lo cual exige un solucionador paralelo de conjugado gradiente (CG). Este proceso genera tres desafíos: alto consumo de entrada/salida, una difícil relación entre regularización y capacidad de expresión, y la incompatibilidad con precisión baja. Parallax aborda estos puntos al eliminar el solucionador. En su lugar, aprende una matriz de proyección adicional, representada como ρᵢ = Wᵣxᵢ, donde Wᵣ es una matriz entrenable que extrae directamente la covarianza entre claves y valores desde la entrada de la capa. Esta solución mantiene el principio de atención local lineal, pero la implementa de forma más sencilla y eficiente, transformando el cálculo per-consulta en una proyección aprendida.
Para el lector peruano, esta evolución en inteligencia artificial tiene un impacto directo en la capacidad de los modelos de lenguaje para procesar información compleja en tiempo real. A medida que los sectores como finanzas, comercio electrónico y educación adoptan tecnologías basadas en modelos grandes, una arquitectura como Parallax puede permitir una mejor precisión en predicciones sin aumentar excesivamente los costos operativos. Esto es especialmente relevante en el entorno peruano, donde las condiciones de infraestructura tecnológica y el acceso a recursos computacionales pueden limitar el uso de modelos altamente exigentes. La solución propuesta no solo mejora el rendimiento, sino que también lo hace más accesible, abriendo puertas a aplicaciones más precisas en entornos locales.