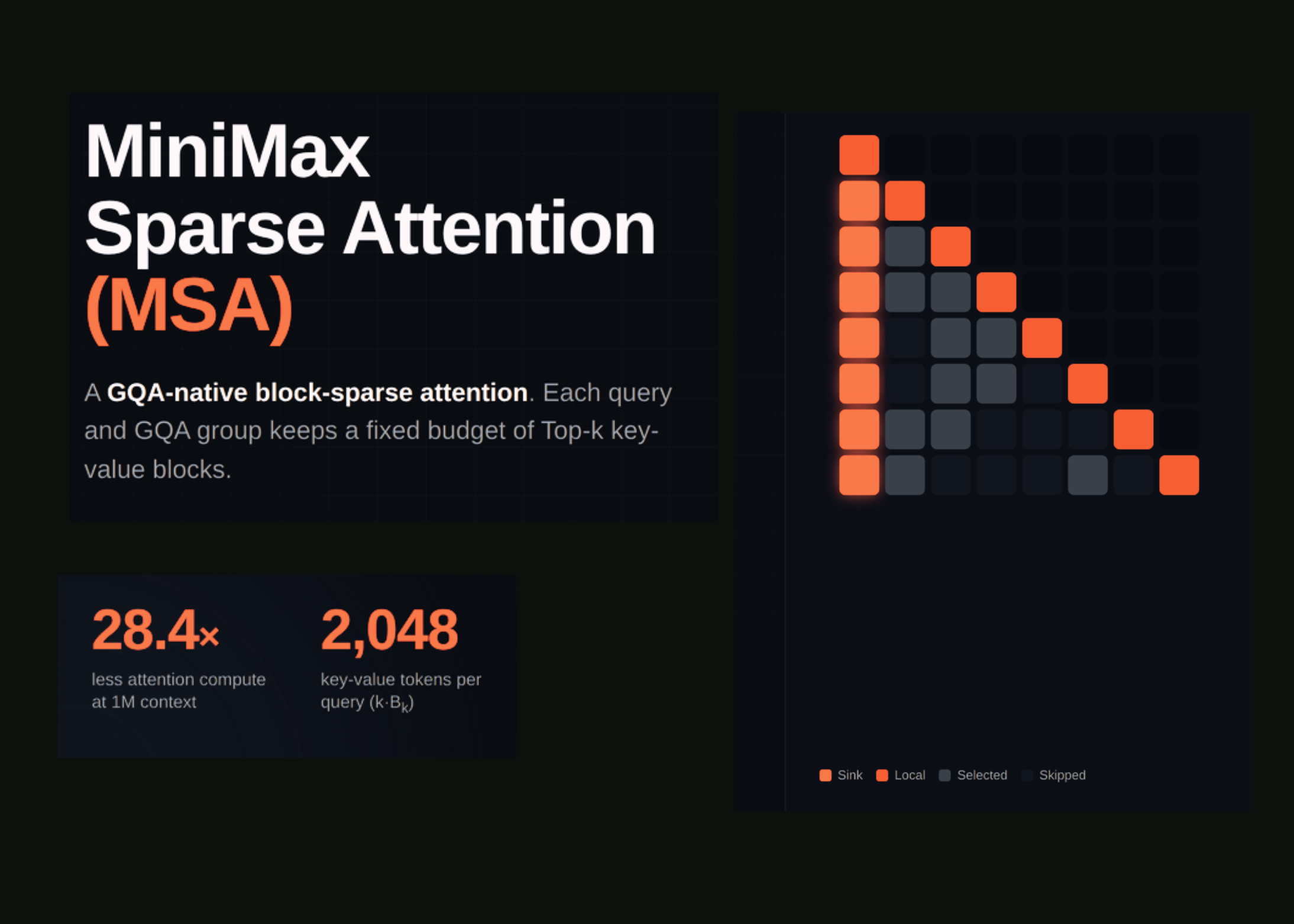
Segun MarkTechPost (AI/ML News), el equipo de investigación de MiniMax ha presentado una nueva técnica de atención denominada Sparse Attention (MSA), diseñada para superar el costo computacional creciente asociado a los modelos de inteligencia artificial de gran tamaño. Esta innovación se basa en un enfoque dual que divide la atención en dos etapas: una de selección y otra de ejecución precisa. El sistema opera dentro de un modelo de 109 billones de parámetros, entrenado con datos multimodales, y ha sido validado en un entorno de producción mediante el lanzamiento del modelo MiniMax-M3.
La estructura propuesta separa el proceso de atención en dos ramas. La primera, denominada Rama de Índice, selecciona de forma eficiente los bloques clave de memoria que cada consulta debe procesar. Cada grupo de consultas (GQA) opera con un conjunto compartido de bloques, de tamaño predeterminado de 128 tokens, y cada consulta se asocia a 16 bloques. Esto limita el consumo de recursos a un presupuesto fijo de 2.048 tokens clave-valor por consulta. La segunda rama, la Rama Principal, ejecuta una atención exacta solo sobre los bloques seleccionados, evitando el cálculo completo de softmax sobre todo el contexto. A diferencia de la atención densa, que escala linealmente con el tamaño del contexto (O(N)), el sistema de MSA mantiene un costo constante (O(kB_k)) que no crece con el aumento de longitud del contexto. Esta característica permite que el modelo maneje secuencias mucho más largas sin un incremento excesivo en el consumo de potencia computacional.
La selección se realiza a nivel de bloque, no por token, lo que optimiza el uso de recursos. Los bloques seleccionados se distribuyen entre grupos distintos, permitiendo que cada grupo se centre en distintos segmentos del contexto. La operación de selección incluye un paso de puntuación y agrupación, donde se identifican los bloques con mayor probabilidad de relevancia. Además, el sistema garantiza que el bloque que contiene la consulta original siempre sea incluido, evitando que se pierda información local crítica. Esta arquitectura ha sido implementada como un kernel de inferencia abierta, lo que permite a otros investigadores y desarrolladores replicar y adaptar el enfoque a sus propios modelos.
Para los peruanos, esta evolución tecnológica resalta la importancia de invertir en soluciones de inteligencia artificial escalables y sostenibles. En un contexto donde las empresas locales enfrentan presiones crecientes por eficiencia operativa y reducción de costos, el avance de MSA puede servir como modelo para desarrollar sistemas de gestión de datos más ágiles. Aunque aún no se ha aplicado directamente en sectores como el retail o la banca, su potencial en procesos de análisis de grandes volúmenes de información —como la gestión de inventarios o el monitoreo de mercados— es significativo. La capacidad de manejar contextos largos sin sobrecargar el hardware abre puertas a soluciones más accesibles, que podrían eventualmente llegar a entornos de pequeñas y medianas empresas en el país.