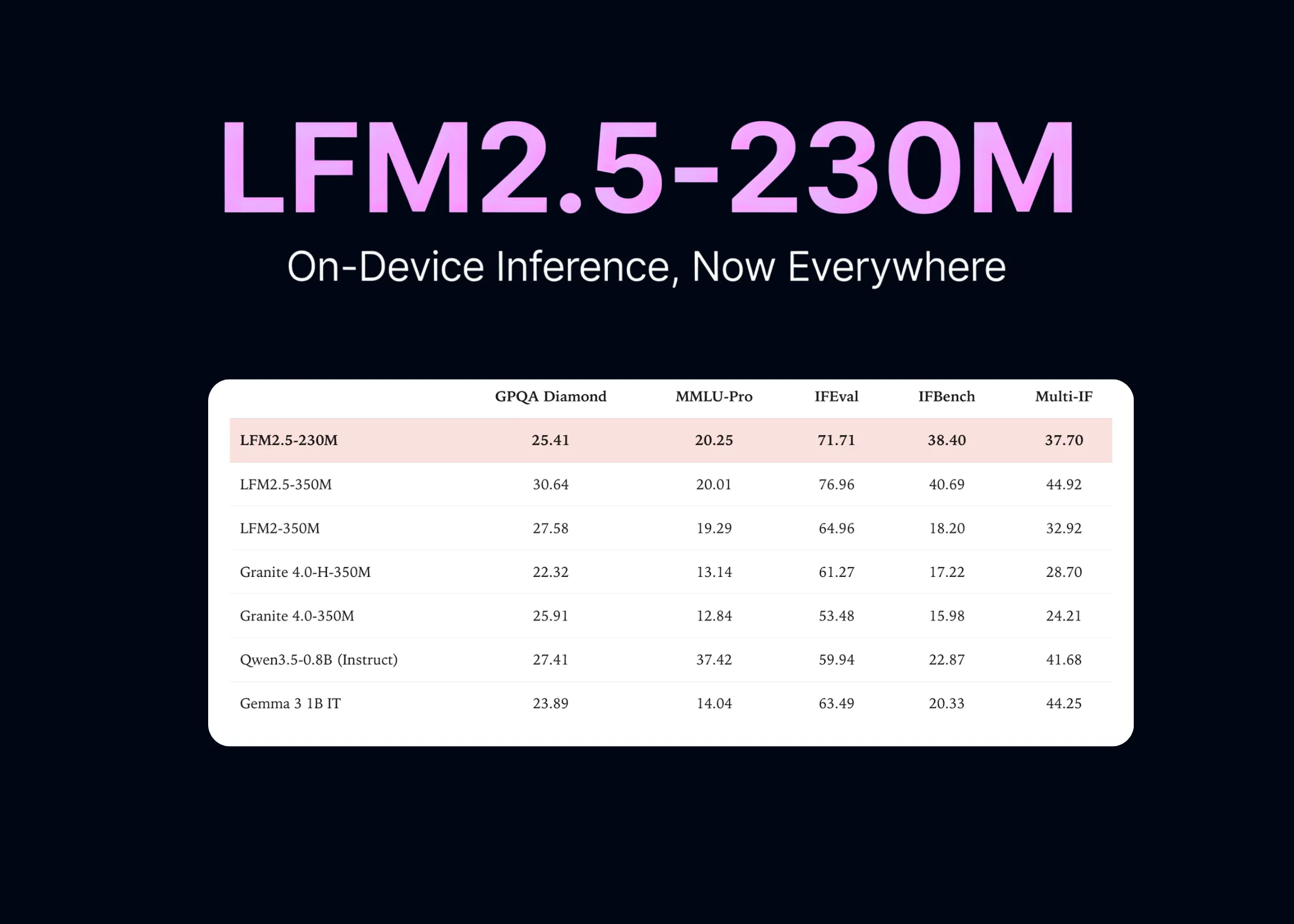
Segun MarkTechPost (AI/ML News), Liquid AI ha presentado su modelo más pequeño hasta la fecha, LFM2.5-230M, diseñado específicamente para tareas agentes en dispositivos móviles, robots y sistemas automatizados. Este modelo, compuesto por 230 millones de parámetros, no busca ser un sistema generalista, sino una herramienta enfocada en extracción de datos y uso de herramientas en entornos de bordo. Su arquitectura, basada en LFM2, integra ocho bloques de convolución doble-gated y seis de atención por grupo (GQA), optimizados para ejecutarse rápidamente en procesadores de CPU. La longitud de contexto alcanza 32.768 tokens, con un vocabulario de 65.536 entradas, y cuenta con soporte para diez idiomas, entre ellos inglés, chino, árabe y japonés.
La capacidad de inferencia se mantiene alta en dispositivos de gama alta: alcanza 213 tokens por segundo en un Galaxy S25 Ultra, mientras que en un Raspberry Pi 5 se mantiene a 42 tokens por segundo. Esta eficiencia lo posiciona frente a modelos más grandes como Qwen3.5-0.8B o Gemma 3 de 1B parámetros, especialmente en tareas de seguimiento de instrucciones y recuperación de información. El modelo está disponible en dos versiones: LFM2.5-230M-Base, para entrenamiento adaptativo, y LFM2.5-230M, versión ajustada para uso general con instrucciones. Ambas variantes son de licencia lfm1.0 y se ofrecen como modelos de peso abierto en Hugging Face.
El entrenamiento se basa en 19 trillones de tokens, incluyendo una fase de extensión de contexto de 32.768 tokens. Posteriormente, se aplica un proceso de fine-tuning supervisado, seguido por una secuencia de optimización que mejora la precisión y la coherencia en tareas específicas. La implementación es inmediata, con soporte directo para entornos como llama.cpp, MLX, vLLM, SGLang y ONNX, lo que permite su integración rápida en sistemas locales sin necesidad de infraestructura en la nube. El tamaño del modelo oscila entre 293 y 375 megabytes, lo que lo hace altamente viable para dispositivos con memoria limitada.
Para el lector peruano, este avance representa una oportunidad clave en el acceso a inteligencia artificial de bajo costo. En un contexto donde muchos usuarios no pueden permitirse servicios de IA en la nube, modelos como este permiten que pequeñas empresas, emprendedores o incluso personas particulares implementen herramientas de toma de decisiones en sus dispositivos diarios. La capacidad de ejecutar inferencia en teléfonos y placas como Raspberry Pi abre puertas a soluciones prácticas en áreas como atención al cliente, gestión de inventarios o procesos administrativos. Aunque no está diseñado para generar código o resolver problemas matemáticos, su eficiencia en tareas de extracción de datos puede transformar la forma en que se gestionan información en entornos locales.