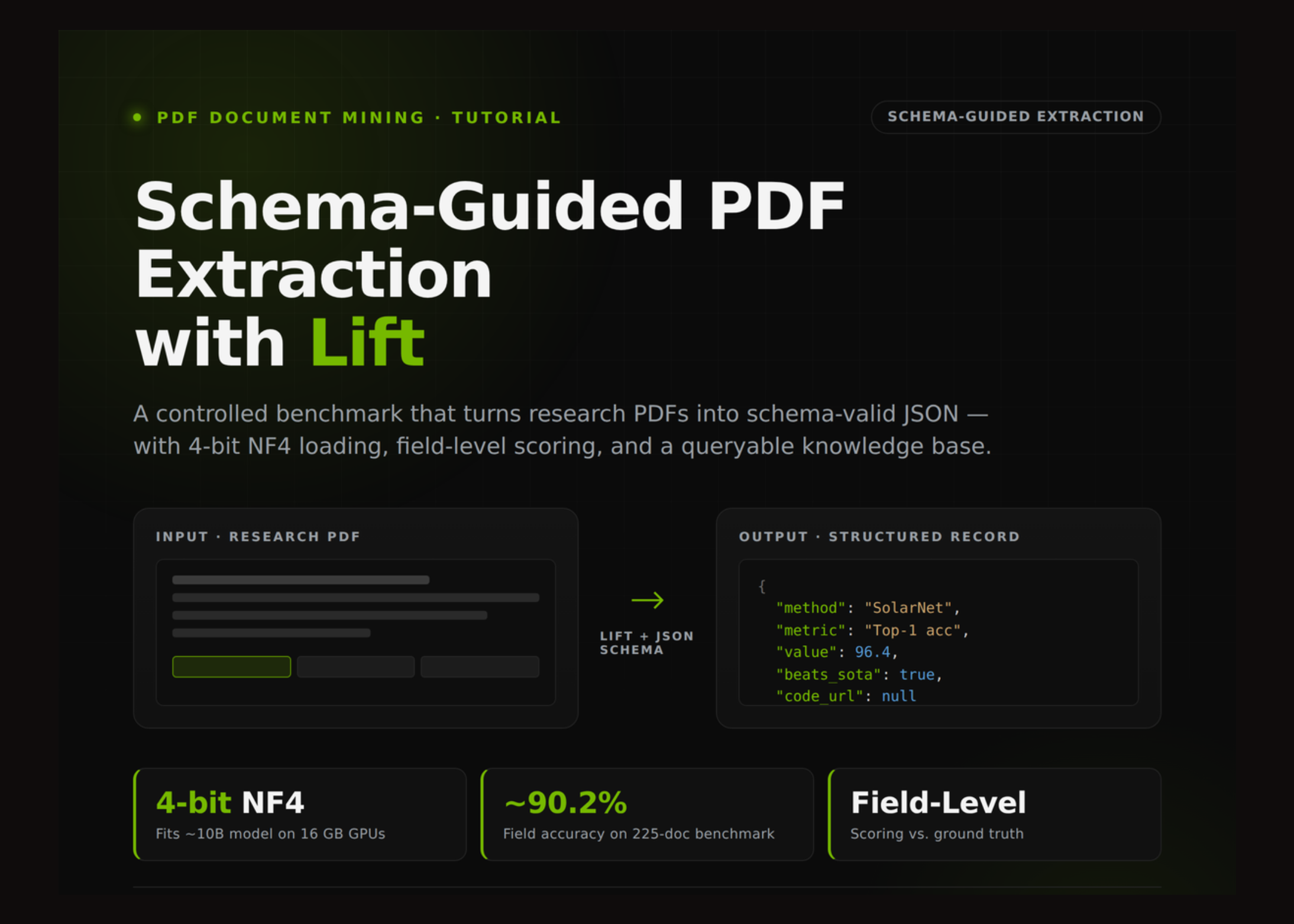
Segun MarkTechPost (AI/ML News), un equipo de desarrolladores ha diseñado un flujo completo para transformar documentos PDF de investigación en datos estructurados, utilizando un modelo de lenguaje especializado y evaluaciones controladas por esquemas. La solución se centra en la precisión del análisis, no en demostraciones rápidas, y permite detectar errores comunes como ambigüedades en métricas, comparaciones entre modelos, ausencia de publicaciones de código o afirmaciones booleanas sobre el estado de la tecnología más avanzada. Para lograr esta robustez, se configura un entorno en Google Colab con GPU disponible, ajustando el modo de precisión a 4-bit NF4, lo que permite ejecutar el modelo de forma eficiente incluso en dispositivos con 16 GB de memoria. Este proceso incluye la generación de informes de múltiples páginas con distracciones intencionales, creando un escenario realista para probar cómo el sistema identifica títulos, autores, conjuntos de datos, parámetros, limitaciones y enlaces a repositorios.
El entorno se prepara mediante la instalación de dependencias clave como reportlab, pypdfium2, pandas y matplotlib, además de librerías específicas para el modelo Lift. Se activa el modo de precisión reducida para optimizar el uso de la memoria, y se asegura que la versión de Pillow coincida con la especificada (11.3.0). Cualquier discrepancia se detecta y se corrige automáticamente, evitando errores en el procesamiento. La configuración permite que el sistema procese documentos reales, como el artículo de arXiv sobre aprendizaje automático, limitando el rango a las primeras cuatro páginas. Este enfoque no solo valida el rendimiento del modelo, sino que también permite evaluar el comportamiento del sistema en distintos niveles de complejidad, desde la recuperación de datos simples hasta la interpretación de afirmaciones técnicas.
Para el lector peruano, esta tecnología representa un avance significativo en la automatización de procesos de investigación. Muchas instituciones, desde universidades hasta empresas de innovación, manejan grandes volúmenes de documentos técnicos sin una herramienta efectiva para extraer sus datos de forma sistemática. Al aplicar este tipo de soluciones, se podría reducir el tiempo de análisis en áreas como el desarrollo de políticas públicas, la evaluación de tecnologías emergentes o la gestión de proyectos de innovación. Aunque aún se requieren ajustes para adaptarse a contextos locales, el potencial para integrar estos sistemas en entornos de gestión de conocimiento es alto. El enfoque basado en esquemas y validaciones permite no solo extraer datos, sino también verificar su calidad, lo cual es clave para tomar decisiones informadas en un mercado donde la información es clave.