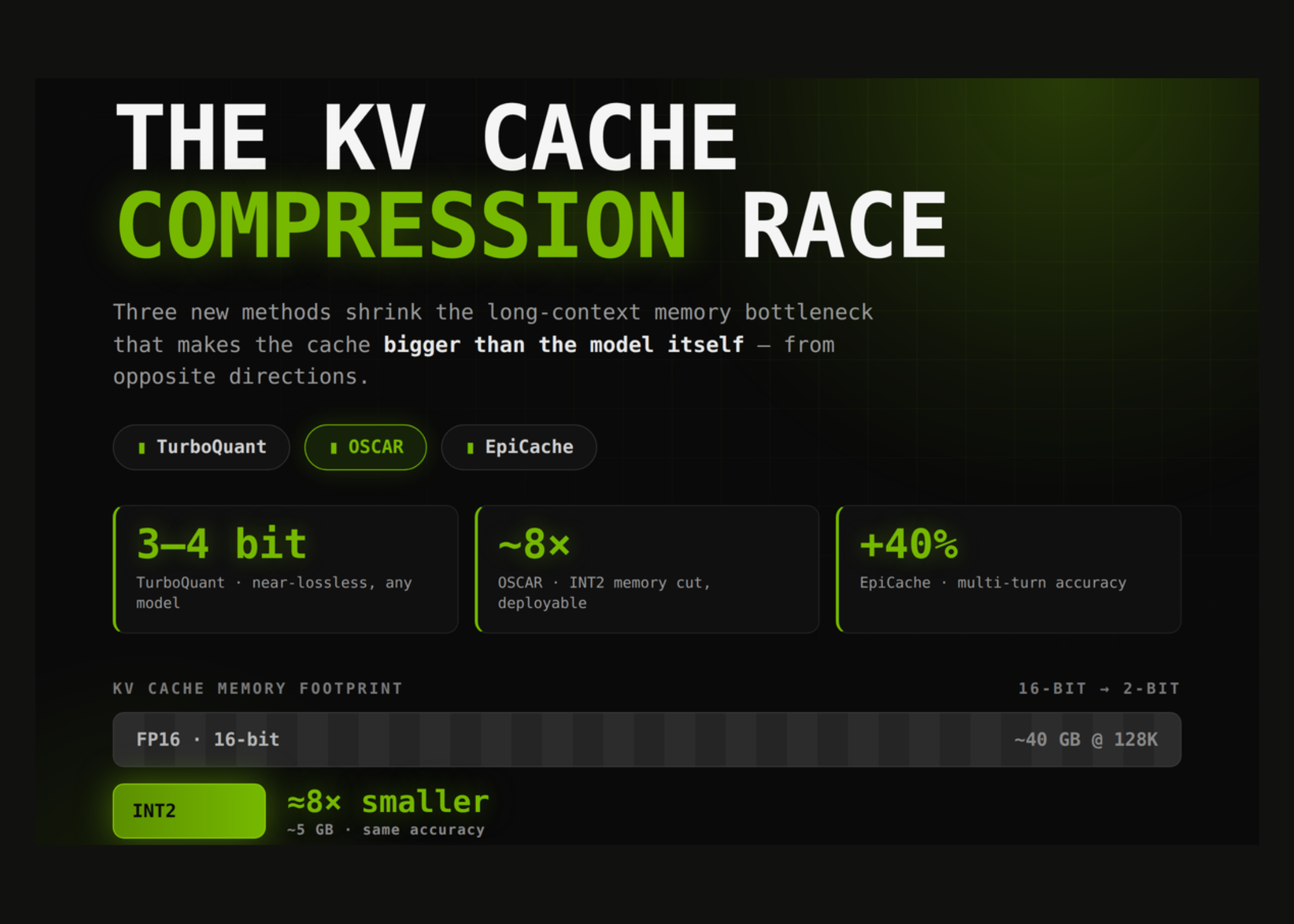
Segun MarkTechPost (AI/ML News), el rendimiento de modelos de lenguaje de larga secuencia enfrenta un límite crítico que no proviene de los pesos del modelo, sino de la necesidad de almacenar en memoria todos los vectores clave y valor (KV) generados en cada token durante el proceso de decodificación. Este almacenamiento se expande de forma lineal con la longitud de la secuencia y el tamaño del lote, y en configuraciones de alto volumen puede superar incluso el tamaño total de los pesos del modelo. Por ejemplo, un modelo como Llama-3.1-70B en precisión BF16 requiere aproximadamente 0.31 MB por token. En escenarios de 128 mil tokens, el consumo de memoria alcanza alrededor de 40 gigabytes; en casos de un millón de tokens, supera los 300 gigabytes, lo que representa una magnitud superior a los 140 gigabytes de peso del modelo en sí. Además, cada nuevo token debe acceder a toda la caché, lo que convierte el proceso de decodificación en una operación limitada por la velocidad de acceso de la memoria, no por el poder de cálculo. Por ello, reducir el tamaño del caché se convierte en la estrategia más directa para disminuir tanto los costos operativos como el tiempo de respuesta.
Los métodos actuales para optimizar este espacio se clasifican en cinco categorías: eliminación de tokens, cuantización, proyección de baja rango, fusión de cachés y diseño arquitectónico compartido. En 2026, se han intensificado los avances en cuantización de baja precisión. Google y la Universidad de Nueva York han desarrollado TurboQuant, mientras que Together AI presenta OSCAR, abordando el mismo desafío desde perspectivas opuestas. Apple, por su parte, introduce EpiCache, que resuelve un problema no abordado por los anteriores. La principal amenaza que enfrentan todos estos sistemas radica en los canales atípicos: unos pocos vectores que presentan magnitudes excesivas, que dominan el rango de cuantización y reducen el espacio disponible para representar el resto del contenido. Así, una cuantización básica como INT2 (solo cuatro niveles) pierde casi toda su precisión. El sistema KIVI estableció un punto de referencia, demostrando que los vectores clave presentan canales atípicos fijos a lo largo de los tokens, mientras que los vectores de valor no. Por eso, cuantiza los vectores clave por canal y los valores por token. Este enfoque sin necesidad de ajustes permite reducir el uso de memoria en un 2,6 veces en comparación con el estado inicial.
Para el lector peruano, este avance tecnológico es relevante porque refleja cómo las empresas de inteligencia artificial están buscando soluciones escalables para operar en entornos de alta demanda. Aunque los modelos de lenguaje aún no están disponibles en el mercado local, su eficiencia determinará el acceso futuro a servicios como asistentes virtuales, plataformas de análisis de datos o herramientas de gestión empresarial. En un contexto donde los costos de infraestructura tecnológica son críticos, el ahorro en memoria puede traducirse en precios más accesibles y servicios más rápidos, lo que beneficiará tanto a pymes como a sectores del sector público.